Architecture
OpenCore is an extendible stack, it’s core components consist of a MongoDB database, it must be a replica set to allow support for change streams. A stateless RabbitMQ (Can be run with durable queues and persistent storage.) OpenCore API and web interface. If deployed in docker, you can spin up multiple NodeRED instances using the API or the web interface. Different types of clients, custom web interfaces, OpenRPA robots, PowerShell modules and remotely installed NodeRED’s can then connect to the OpenCore API using web sockets and receive events and data. Clients will use the API to register/publish queues and exchanges in order to add an extra layer of authentication and to simply for network requirements. All database access is exposed as natively close to the MongoDB driver, but with an added layer of security though the API.
If installed the basic docker-compose file that would make something like this.
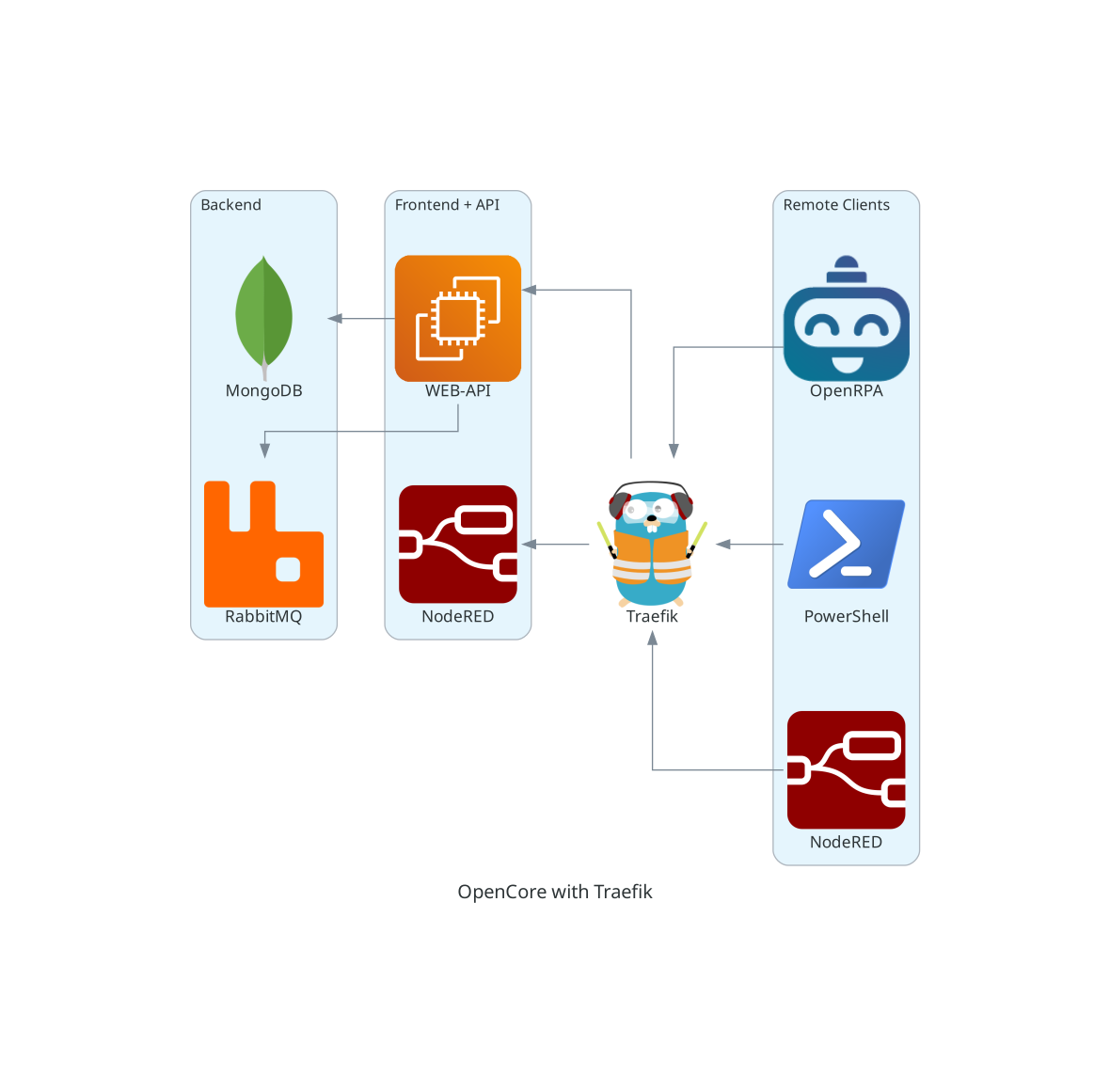
For bigger installations we recommend using kubernetes, we supply an easy to get started with helm chart, that also supports very complex demands. Besides adding easy access for running geo distributed installation ( multiple data centers ) of a single OpenCore install, it also adds more layers of security and much needed fault tolerance and scalability. This is usually also when we want to add better monitoring of the core components and support for designing graphs and dashboard based on data in OpenCore.
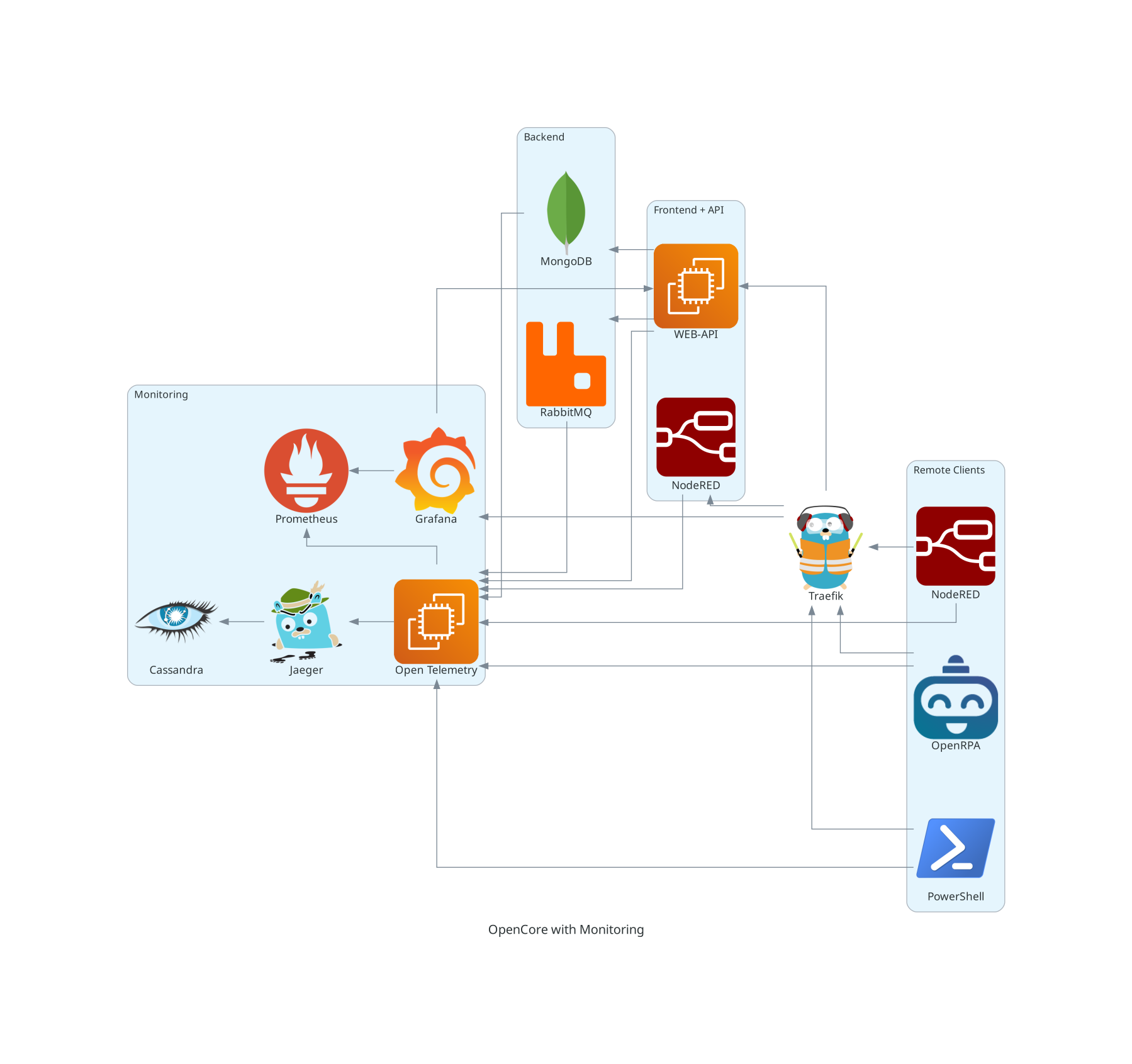
When running in high secured network, where you need to control the direction and priority the flow of data and events, OpenCore can be deployed in mesh topologies. This can also be useful if working in distributed networks where network outage can last for very long periods of time, and the local storage of a remote NodeRED is not enough, or you need access to the web interface and reports even when the network is down.
Running on kubernetes, requires a premium license, see here for more details.